Partitioning theory made simple

Table of Contents
Congratulation, your application is successful, you have many active users!
That means that more and more data is accumulating in your systems, and your database is starting to get clogged up with the increasing amount of data it accumulates, each query having to scan over more and more rows.
How to deal with that ?
Partitioning #
It is one of the solution to increase the scalability of our database or any kind of storage (queues, file systems, indexes, etc…).
Basically it involves splitting up our data, in smaller chunks each called partitions/shards: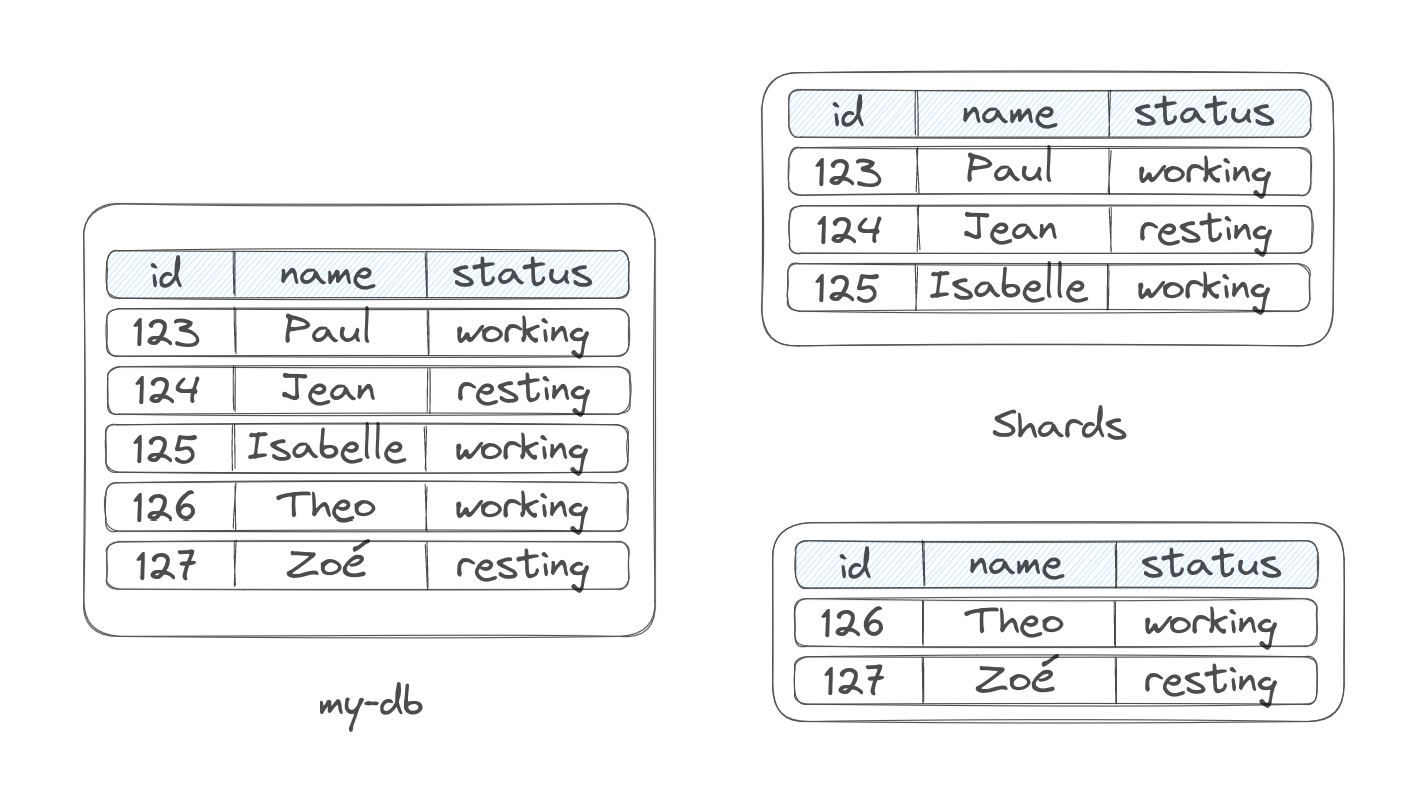
Above is shown an example of horizontal partitioning. Where we split the data by rows based on a partition key.
Each partition is stored and can be then accessed separately to improve the performance of the queries. In the example above, each partition may be marked as a range of IDs. So, for any range query, the result can be found without going over all the data in the storage. Only a partition of the storage can return us, or not, the result of a query on an ID.
e.g: if we wanted to get all the rows with ID=124, we could scan only the partition ranging from ID=123 to ID=125.
Vertical partitioning #
In vertical partitioning, we are splitting the columns of a table into multiple partitions.
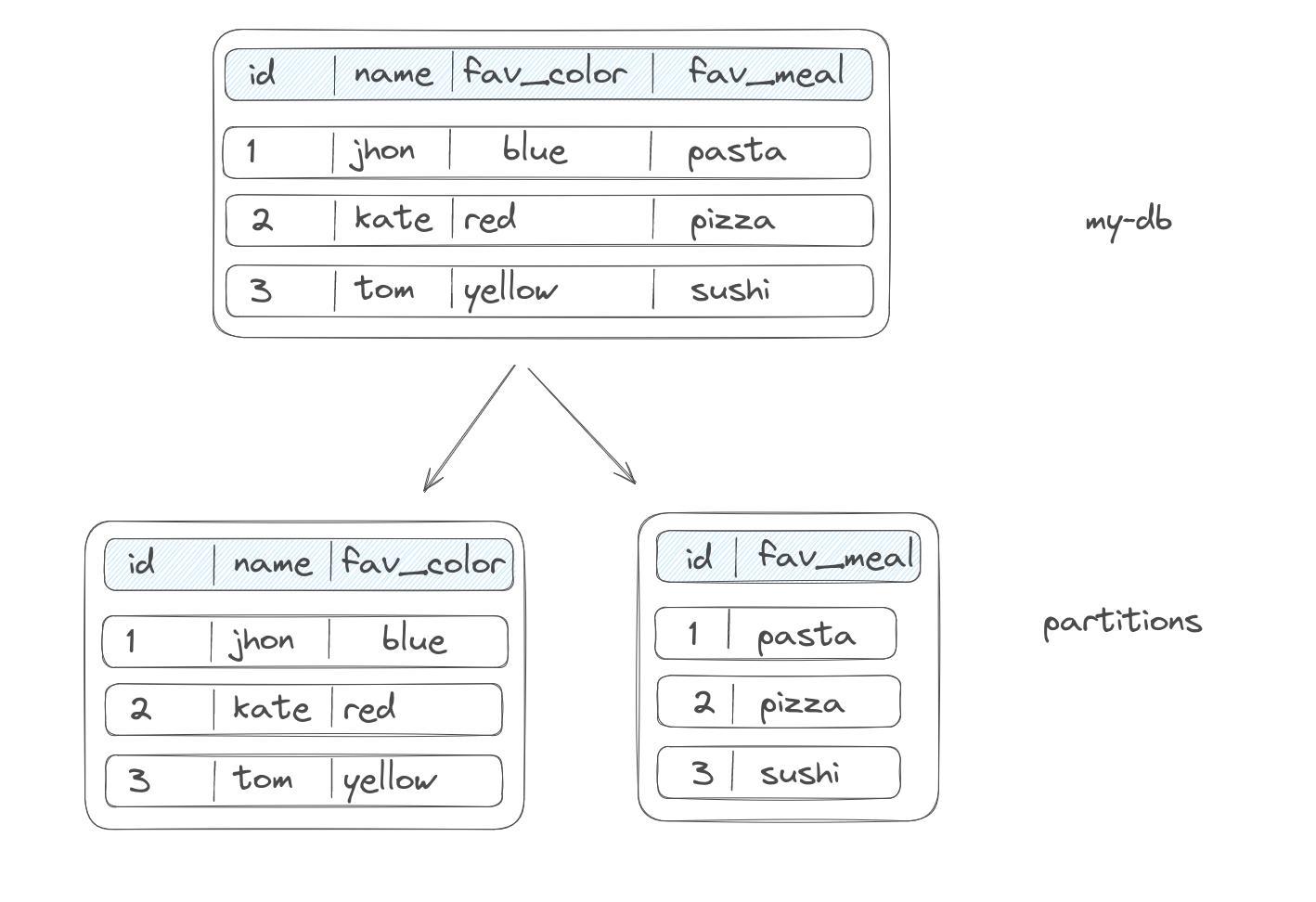
This can be very efficient when some columns are accessed more frequently than others. But if a query needs to span multiple partitions, combining the result may end up in more overhead than initially needed.
This kind of partitioning is less frequent than the next one.
Horizontal partitioning #
It involves splitting the data by rows. We could theoretically distribute our data randomly over the different partitions, but it is not a good idea: How are we supposed to know where to find our data when we want it back ? We would need to go over all the partitions and do a full scan.
To solve this, we have multiple solutions:
Range based partitioning #
If our data consisted of a list of users, and one of the column being the first name of our users, we could simply split the partitions over ranges of the letters in those names. For instance, one partition would be the for the names beginning by the letter ‘a’ to the letter ‘c’. The second partition letter ’d’-‘f’, then ‘g’-‘i’, etc…
This works well on multiple cases, because we can very easily distribute our partition as shards on multiple computer, without having to query multiple of them as we know on which partition to find a user named ‘bob’.
One big cons here is that we can encounter hotspots: In our example, we would probably would have a partition for the names beginning by the letter ‘x’-‘z’. But there are in reality very few names that would end up on that partition, hence it would be less accessed. On the contrary of the partition ‘a’-‘c’, which will be way more accessed than the other partitions, and can then be described as a hotspot.
A hotspot (and the node holding it) would store more data than the other partitions, but also handle more queries, write, reads, etc… and also
Side note: A Hotspot and Data Skew, are related concepts, but describe different things:
- A Hotspot occurs when a specific partition or node in the system receives a disproportionately high volume of traffic or requests compared to others. This can be caused by the nature of the data being accessed or by the way it is distributed.
- A Data Skew refers to an uneven distribution of the data across multiple partitions or shards in a storage system. This will usually lead to some partitions having much more data than others, which will cause uneven resource utilization and performances across the partitions/shards.
Hash range based partitions #
To solve the issue of hotspots on standard range based partition, we can involve a hash function.
What we can expect from a hash function, is to take an input and output a result that is evenly distributed over some criteria. For instance, we can imagine a hash function that would take any string as an input, and output the corresponding number from 1 to 100:
hash("bob") -> 48
hash("alice") -> 27
hash("tom") -> 81
hash("bob") -> 48
We can use that hash function to take one column of the data we want to distribute, then create partitions based on the output of our hash function: first partition 1-10, second partition 11-20, etc…
We would encounter fewer hot spots. Unless if among values of the key we feed our hash function, there was one or multiple very popular ones (e.g, if in the country of our application, 60% of the people were named “bob”)
Also, we are unfortunately giving on data locality for range queries, which was a huge pro of the range based partition. But there is a way to rectify this problem.
Secondary index #
Using a secondary index, we can gain back the benefit of efficient range queries with our data that is partitioned with hash ranged based partitions.
A secondary index basically is an additional copy of our data, where we store it in a different sort order.
For instance, if we had to store the height of our users, we could create a secondary index (sql CREATE INDEX users_height ON users height;). Most modern database systems optimize the queries run on data that has been indexed, by using the relevant indexed under the hood.
With a secondary index in the context of partitioned data arise the issue of maintaining the index. For that we have two solutions:
- Local secondary index (LSI) : We keep a secondary, sorted copy of our data (index) for each partition. The pros being that writing new data is efficient since it happen in only one local index (in a given partition). But unfortunately, even though we can binary search on each index, this would lead us to still read from each partition if we every need to find a user with a given height (finding some indexed data will require going through all partitions since they are split on other criteria). This solution is better for a write-heavy use case.
- Global secondary index (GSI): We keep a secondary, sorted copy of our data (index), but that has scope over the entirety of our dataset. And we then split this secondary over the different partitions. For instance, we could decide that on partition 1 would go the part of the index with all the users of height 5"8 or less, on shard 2 users from 5"9 to 5"11, etc… This would allow us to read from only one partition when we searched for data over the height of our users. The biggest con being that a user that has been located to a partition X by the hash range based partitioning might end up on partition Y’s secondary index. To mitigate the risk of insistent partitions (one of the two rights, for the same data, on two different partitions), we want to involve distributed transactions. This solution is better for read-heavy use case.
What about Sharding ? #
Basically, sharding is the fact that different partition are stored and managed by discrete servers, usually in a cluster, where each machine can be described as a node.
Shards can be replicated across different nodes to increase availability and reliability. And in a cluster, different orchestration processed handle the backup and restoration of shards to mitigate individual nodes failures (hardware or software).