Database replication vs sharding

Table of Contents
When using database with applications at scale, every part of tech stack end up facing scalability issue. Databases encounter a unique set of issue to solve, which requires unique techniques.
Database replication #
In a pretty transparent manner, database replication means that we replicate, or in other words, create and maintain copies of our database across multiple servers for instance.
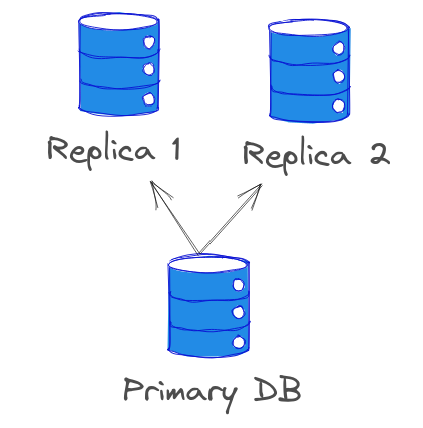
The simplest version of a database replication would be the above schema, a primary database with two replicas of the primary database.
There are multiple ways to handle the read operations within a replication environment. Some of them being:
- Load balancing: Using a load balancer in front of our replicas, we can distribute the incoming read requests across the replicas in a balanced manner.
- Read preference: Through configuration of our application, we can direct some read operations to the primary database (operations that would need real time data), while we direct the rest of the read operations to the replicas
Handling write operations in a replication is more complex, since that data consistency is put at risk, the write operations have to be propagated through the whole cluster of databases. The way this issue is usually handled is that, the primary database, serves as a master node, which makes it responsible for processing the write requests.
The main concept to remember is the propagation: When a write operation is successfully executed on the primary database, the changes are propagated to all the replicas.
Advantages of replication #
The replicas can be queried, for read operation for instance (which is the most usual bottleneck in db scaling issues), and which would lighten the IOPS on the primary database, improving the read performance.
These replicas will also increase the availability of our service, as the failure of a replica is not a blocking event for the whole system, and even the failure of the primary database can be managed by allowing a replica to take over this role.
Geographic distribution is also a noticeable upside of replication, as different replicas can reduce the network latency by being placed in different geographical regions.
Database sharding #
It is when partition horizontally a larger database, in smaller and more manageable pieces called shards. Each of these shards then contains a subset of the data and operates as an independent database.
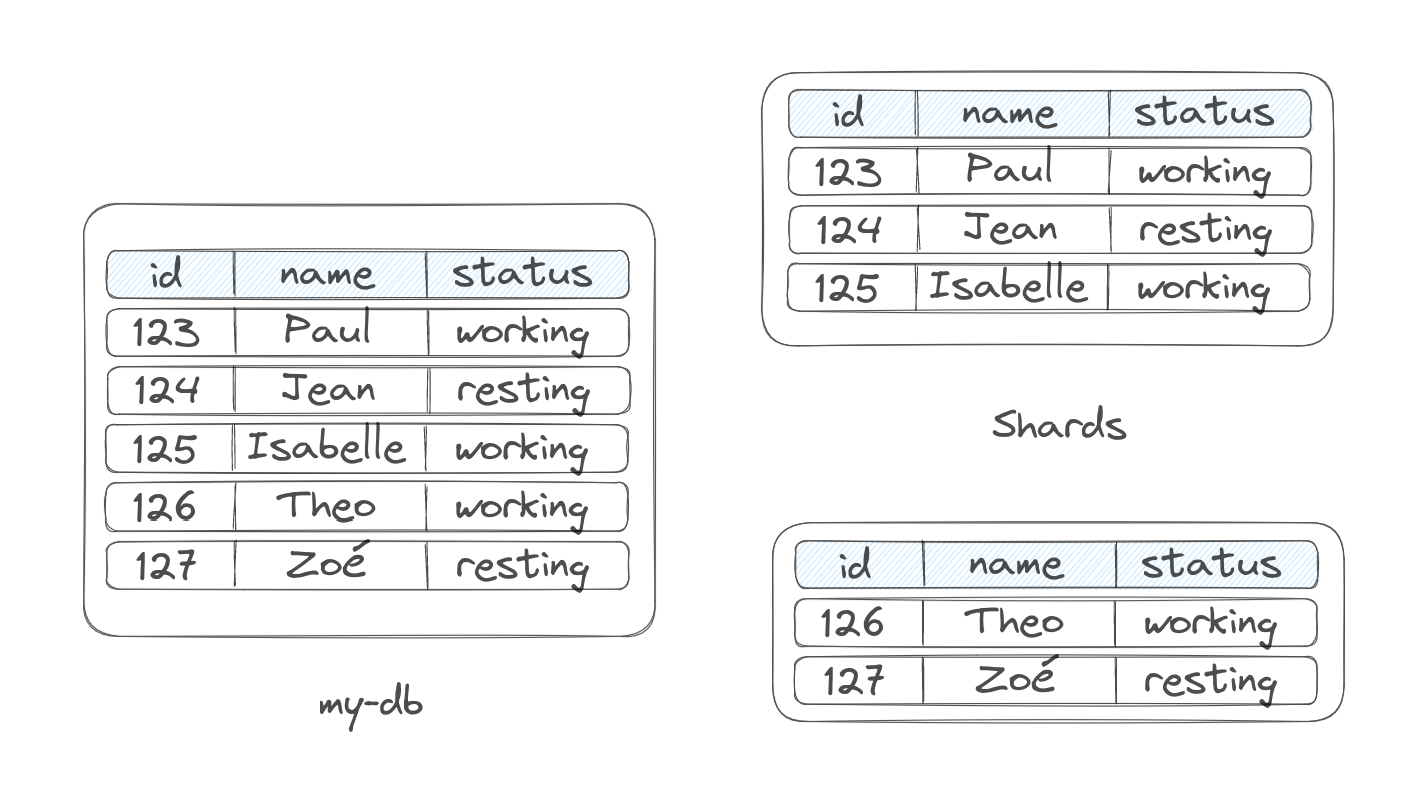
We use sharding usually to handle the challenges of write scalability, as it is adapted for this use case. In a setup where you would reach write contention (multiple write requests competing for the same resources) sharding spread out the write operations to the different shards, migrating the impact of write bottleneck.
Sharding allows horizontal scaling: As the data grows, we can add other shards, with each proportions handling a portion of the data and its associated write load. Each of these shards can be located on a new server or cluster to accommodate to increasing demands.
The data is usually divided based on certain criteria, like:
- The range of values: Splitting the rows into contiguous ranges that respect the sort order of the table based on the primary key column. e.g: ids that go from 1 to 5M, then from 5M to 10M, etc…
- Hash function: The data is randomly distributed in an even manner, across the different shards through a simple algorithm implying a hash function.
Advantages of sharding #
The write scalability is significantly enhanced by distributing the operations to the different shards.
Sharding our data is also cost-effective as distributing the data across multiple servers allows optimizing the resource utilization.
What about partitioning #
Partitioning is just a more generic term for dividing data across tables or databases. Sharding is one of the types of partitioning, where the multiple shards are distributed across multiple database instances (different nodes).